Optimize Unreal Engine builds with BuildGraph and CircleCI
Today, we’re taking a playful twist on being green by recycling a treasure trove of CI wisdom. You see, in a not-so-distant cyber land, I collaborated with CircleCI to conjure up a tech tale that has already been brought to life. But fear not! Just like a well-loved book gets a fresh cover, we’re repurposing this valuable content to breathe new life into our journey through the realm.
Thank you ChatGPT for that entertaining introduction, this first post is very targetted to the Game Development community that build games using Unreal Engine and want to learn how to use CircleCI and Unreal Engine’s BuildGraph to build their games. This is based on work I’ve done at Vela Games to optimize the build pipeline of Evercore Heroes.
With the development of our game quickly ramping up during 2022, and more people joining our team we started to experience bottlenecks in our Jenkins CI infrastructure due to the volume of commits and also because of how our pipeline was structured. Every step (build, cook, package, and gameserver deployment) happened sequentially and was taking up to 2.5 hours to complete in some cases.
As a side note, we were also developing game-supporting projects in different technologies. The barrier to entry for automating some of those projects in Jenkins was higher than we expected and we wanted to explore other options to reduce complexities for our engineers, thereby allowing them to focus more on developing products rather than building process automation.
We decided to migrate our Jenkins pipelines to CircleCI to improve on these issues. We first focussed on the build process of Evercore Heroes, our goal was to reduce the game build times as much as possible by parallelizing and spreading out the different stages onto different agents.
This lead us to leverage Unreal Engine’s BuildGraph technology, CircleCI’s Dynamic Configurations, and self-hosted runners. With these, we were able to reduce our build time up to 85% in a best-case scenario.
This tutorial is heavily based on the work we did and will show you how to leverage CircleCI’s Dynamic Configurations and self-hosted runners to accelerate the build, cook, and packaging stages of your Unreal Engine 5 project by using BuildGraph to distribute the process across multiple runners. All code shown in this tutorial can be obtained from GitHub.
This tutorial covers
- Deploying a self-hosted runner on AWS
- Create a BuildGraph script to package an Unreal Engine Project
- How to translate a BuildGraph script to CircleCI’s Dynamic Configuration
Out of the scope of this tutorial
- How to create an AWS Custom AMI with Unreal Engine 5 Source Code
- How to auto-scale self-runners based on CircleCI’s unclaimed tasks (will have a separate post on this specifically)
Prerequisites for this tutorial
- CircleCI account
- AWS account and knowledge on how to deploy EC2 instances.
- Linux and Windows AWS AMIs with Unreal Engine 5 Source code.
- A fast shared Storage between all your self-hosted runners. I will be using AWS FSx for OpenZFS.
- An Unreal Engine 5 Project (we will be using the First Person Shooter Example included in Unreal Engine)
What is BuildGraph?
Is a script-based build automation system included in Unreal Engine that features graphs of building blocks common to UE projects.
BuildGraph scripts are written in XML, where we define nodes with dependencies between each other.
Each node consists of tasks executed in sequence that expects (depending on configuration) inputs and produce an output.
The inputs and outputs are defined using “Tags”, these have the form of “#MyTag”. By defining the input expectation BuildGraph forms a dependency graph that it uses to determine what kind of dependencies each node has to be able to perform the configured task; these are shared between jobs using shared storage as each node could be running on different Physical Nodes.
BuildGraph scripts are created with the following elements:
- Tasks: Actions that are executed as part of a build process (compiling, cooking, etc.).
- Nodes: A named sequence of ordered tasks that are executed to produce outputs. Before they can be executed, nodes may depend on other nodes executing their tasks first.
- Agents: A group of nodes that are executed on the same machine (if running as part of a build system). Agents have no effect when building locally.
- Triggers: Container for groups that should only be executed after manual intervention.
- Aggregates: Groups of nodes and named outputs that can be referred to with a single name.
We will only be using the first three elements in this tutorial. There are also Flow Control nodes like ForEach and Conditionals that we will be using to make our script more dynamic and do different things based on input.
BuildGraph integrates deeply with UnrealBuildTool, AutomationTool and the editor allowing you to orchestrate, compilation, cooking and packaging of your game across different platforms.
At the time of writing there’s a disclaimer when using BuildGraph:
- The XML scripts currently can only be located within the Unreal Engine directory
- There’s a bug where BuildGraph fails due to produced artifacts being supposedly changed when they actually haven’t
Due to the above we patch buildgraph to be able to have the XML scripts within our game repo and to allow “mutation” of files to circumvent the issue.
Credit to June Rhodes from Redpoint Studios for discovering and patching these issues.
We will be providing the git patch on the GitHub Repository.
CircleCI Dynamic Configurations
If you use CircleCI already and you don’t know Dynamic Configuration, then you are used to defining your workflows purely in YAML.
Dynamic configurations allows you to define your complete workflow within an already running workflow called setup, and you can do this using any programming language you want as long as the output is an accepted CircleCI YAML definition.
Once you have that YAML we call the /api/v2/pipeline/continue endpoint from the CircleAPI passing the YAML definition that should be used to create the dynamic workflow. For this step we will use the Continuation Orb as it greatly simplifies this.
We will be taking advantage of this feature by defining our whole workflow based on what BuildGraph determines we have to do as defined on our XML script.
To be able to use this feature you have to enable it on Project Settings > Advanced > Enable dynamic config using setup workflows

CircleCI Self-hosted runners
Another important feature for us are the self-hosted runners, this allows to run CircleCI jobs on your own Infrastructure (in our case EC2 instance on AWS).
Our build process requires really large resource types that aren’t available on CircleCI’s Cloud platform, and self hosted runners allow us to access the custom compute resources we need.
When using this you are responsible for building your own infrastructure with any software you need for your workflows to run successfully, in our scenario we need to package the Unreal Engine source code within the AMI we will use for deploying these runners.
How to build an AMI with UE is not part of the scope of this tutorial, but I would recommend you using Packer for building the AMI and the UE source can be access on Epic Games’ Website. There’s documentation on how to build the engine on the Unreal Engine’s Github repository.
Let’s get started
For this tutorial, we will be using the First person shooter example that comes with Unreal Engine.
We are going to create a BuildGraph script to compile, cook and package the project on both windows and Linux; we are going to take this and create a python script to translate BuildGraph to a CircleCI dynamic configuration.
The BuildGraph script will be the owner of all core pipeline logic and will be determining what runs and where. We will run BuildGraph in the setup stage of our Dynamic Configuration using a special flag that instructs BuildGraph to output only the Graph as a JSON which we will then pass to our python layer as a parameter and output the final workflow in YAML.
The end result will be a ZIP file containing the game binaries that will be uploaded as an artifact.
Deploying the self-hosted runners
In this section, we will be configuring and deploying the self-hosted runners that our workflows will run on. These will be responsible for building, cooking, and packaging our example game.
-
Create a resource class for linux and for windows instances using CircleCI CLI or the Self-hosted runner Web UI.
We will use the CLI:
$ circleci runner resource-class create vela-games/linux-runner-test "For CircleCI Tutorial" --generate-token api: auth_token: f5dfdc41d7973864e9f625a897b755fea5ac17ecdf519732b81b87a309467bf20698fbdbc04a8b94 +------------------------------+-----------------------+ | RESOURCE CLASS | DESCRIPTION | +------------------------------+-----------------------+ | vela-games/linux-runner-test | For CircleCI Tutorial | +------------------------------+-----------------------+ - No matter which option you choose after the creation of the resource class an
auth_tokenwill be provided, you need this when configuring the agent on your instances. -
Deploy your instances configuring the
resource-classandauth_token.I’m a firm believer of Infrastructure-as-code and GitOps-driven workflows with peer-reviewed changes, Terraform aligns perfectly with this ideology and we use it to deploy our self-hosted runners.
I’m open-sourcing an example of how to deploy the self-hosted runners for this scenario using Terraform, this is heavily based on what we use internally at Vela.
You can find the repository here, you are welcome to fork it and use it.
This module uses an AutoScaling Group for each runner resource class, this makes it very simple to scale in and out instances when we need them as we can define a Launch Configuration once and reuse it across all the EC2 instances we need. This also gives you a foundation to autoscale runners based on job queue in the future if you want.
BuildGraph needs a shared storage to share artifacts between running jobs, for this we’ve chosen to use AWS FSx for OpenZFS as it provide us with:
- OS-agnostic accessibility by being able to mount the filesystem over NFS Protocol. This is important for us as we will be building on both Windows and Linux machines
- Very low latency when accessing files, very useful for almost instant metadata operations which Unreal executes a lot to check for files it has to pull for the build.
- When applying the Terraform module it will:
- Create an AutoScaling Group per resource class you configure
- The AutoScaling group will be deployed by default with a scheduled action to scale in or out based on a cron expression. We do this as to not have instances running at times when we are not expecting pipelines to run and save some money.
- Deploy an FSx for OpenZFS filesystem we will use to have a Shared DDC and for BuildGraph to share artifacts between running jobs.
- Each EC2 instance will be deployed with a user-data script that will install the CircleCI agent and configure the FSx mount. In the case of windows it will be creating a ps1 script to mount FSx when we run the pipeline, for Linux it’ll get mounted as part of the user-data execution.
-
To use our module make sure to create a tfvars file configuring the
subnet_idsfor your deployments and yourvpc_id. Setting up these network resources on AWS is out of the scope of this tutorial, but I recommend you look into using the AWS Terraform VPC Module.The auth_tokens for each of your resource classes have to be configured as a map in the
circleci_auth_tokensmap, the value has to be in the following format:{ "namespace/resource-class": "your-token" }Treat the tokens as sensitive values, at Vela we use Terraform Cloud and we configure the
auth_tokenmap as a sensitive variable on our workspace.Within the
runners.auto.tfvars` file you can configure a list of the runners you want to deploy. This is an example on how to use it:runners = [{ name = "namespace/linux-resource-class" instance_type = "c6a.8xlarge" os = "windows" ami = "ami-id" root_volume_size = 2000 spot_instance = true asg = { min_size = 0 max_size = 10 desired_capacity = 0 } key_name = "key-name" scale_out_recurrence = "0 6 * * MON-FRI" scale_in_recurrence = "0 20 * * MON-FRI" }, { name = "namespace/windows-resource-class" instance_type = "c6a.8xlarge" os = "linux" root_volume_size = 2000 spot_instance = true ami = "ami-id" asg = { min_size = 0 max_size = 10 desired_capacity = 0 } key_name = "key-name" scale_out_recurrence = "0 6 * * MON-FRI" scale_in_recurrence = "0 20 * * MON-FRI" }]Make sure that the
nameis equal to theresource-classname you creates previously as this is used to get the auth_tokenfrom the map.If you decide to deploy the agents without using our TF module, check the docs on how to install it, make sure you have a fast shared storage solution that all runners can connect to, to share intermediate files between jobs.
Creating the BuildGraph script
If this part is of no interest to you, you can find the full script here and move on to the next part of the tutorial.
As mentioned we will be using the First Person shooter example that comes with UE 5.0, you can create a new project from scratch using the UE Editor or take it from our example in GitHub.
Now that we have our self-hosted runner infrastructure running, we can move to creating the BuildGraph script that will be handling all the work on our pipeline.
The aim for this script will be to:
- Compile the editor for cooking
- Cook using the editor binaries
- Compile the game
- Package the game
And this will happen for both linux and windows platforms. We will be creating some parameters that we can pass in to BuildGraph from the command line.
Create a new folder on your project called Tools, inside of it create a BuildGraph.xml file.
Creating the top node
We start by definining the root/top node for our script:
<?xml version='1.0' ?>
<BuildGraph xmlns="http://www.epicgames.com/BuildGraph" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.epicgames.com/BuildGraph ./Schema.xsd" >
<BuildGraph/>
Inside of <BuildGraph> is where all of our script will live.
Creating some input options
We are first going to include some <Option> nodes, these are parameters that can be passed in from the CLI and we can use to do either interpolate them or change the behaviour of our script.
The value for these options can be restricted using a regex expression, and they can have a default value. Also the value can be a semicolon-separated list that we can use within a <ForEach> node to dynamically create new nodes.
<?xml version='1.0' ?>
<BuildGraph xmlns="http://www.epicgames.com/BuildGraph" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.epicgames.com/BuildGraph ./Schema.xsd" >
<Option Name="ProjectRoot" Restrict=".*" DefaultValue="" Description="Path to the directory that contains the .uproject" />
<Option Name="UProjectPath" Restrict=".*" DefaultValue="" Description="Path to the .uproject file" />
<Option Name="ExecuteBuild" Restrict="true|false" DefaultValue="true" Description="Whether the build steps should be executed" />
<Option Name="EditorTarget" Restrict="[^ ]+" DefaultValue="FirstPersonGameEditor" Description="Name of the editor target to be built, to be used for cooking" />
<Option Name="GameTargets" Restrict="[^ ]*" DefaultValue="FirstPersonGame" Description="List of game targets to build, e.g. UE4Game" />
<Option Name="GameTargetPlatformsCookedOnWin" Restrict="[^ ]*" DefaultValue="Win64" Description="List of the game target platforms to cook on win64 for, separated by semicolons, eg. Win64;Win32;Android"/>
<Option Name="GameTargetPlatformsCookedOnLinux" Restrict="[^ ]*" DefaultValue="Linux" Description="List of the game target platforms to cook on linux for, separated by semicolons, eg. Win64;Win32;Android"/>
<Option Name="GameTargetPlatformsBuiltOnWin" Restrict="[^ ]*" DefaultValue="Win64" Description="List of the game target platforms to build on win64 for, separated by semicolons, eg. Win64;Win32;Android"/>
<Option Name="GameTargetPlatformsBuiltOnLinux" Restrict="[^ ]*" DefaultValue="Linux" Description="List of the game target platforms to build on linux for, separated by semicolons, eg. Win64;Win32;Android"/>
<Option Name="GameConfigurations" Restrict="[^ ]*" DefaultValue="Development" Description="List of configurations to build the game targets for, e.g. Development;Shipping" />
<Option Name="StageDirectory" Restrict=".+" DefaultValue="dist" Description="The path under which to place all of the staged builds" />
<BuildGraph/>
I’ve added a Description for each of the options so you have some context on each one of them.
As you might see from the created <Option> nodes we will be keeping the compile-cook-pak process separate for each platform in this example, cross-compiling is supported in UE for some platforms as long as they are built from Windows, but I want you to see how we are going to approach selecting where our jobs should be running for different self-hosted runner OSes.
Creating properties
Next we are going to add some <Property> nodes, these are like variables that we can read and write in different stages of our script, as we will be using <ForEach> to iterate through some of the <Option> we created, we will be using them to aggregate all created tags.
<Property Name="GameBinaries" Value="" />
<Property Name="GameCookedContent" Value="" />
<Property Name="GameStaged" Value="" />
<Property Name="GamePatched" Value="" />
Creating Agent Nodes
An <Agent> will define a set of nodes that will run on a specific type of instance. (Either linux or windows).
The definition looks like this:
<Agent Name="Windows Build" Type="UEWindowsRunner">
<Agent/>
Both Name and Type can be anything, for Name we are going to set something explanatory for what will be run inside of it. The Type is the most important thing here, as we will be using this to determine on which CircleCI self-hosted runner resource class all jobs within this <Agent> will run. This will happen on our Python translation layer.
We are going to limit the types to:
UEWindowsRunner- meaning it runs on windowsUELinuxRunner- meaning it runs on Linux
We are going to be creating 7 of these <Agent>, they are:
- 3 for linux build (compile, cook and packaging on linux)
- 3 for windows build (compile, cook and packaging on windows)
The last one it’ll be an aggregate to be able to tell BuildGraph that we want to run all jobs
Let’s start with Windows Agents (build, cook and pak)
We first define a node that will compile our Editor and tag the produced output as #EditorBinaries so we can use them to cook our assets later.
The second part will iterate using <ForEach> through all the target platforms that we allow to be built on Windows nodes, and through every configuration we are targeting our game (this could be Development and/or Shipping).
These will (depending on our <Option> input) create multiple nodes, that will in parallel compile the game for multiple configurations and platforms on windows, and tag the produced output to be shared for subsequent jobs that depend on them.
As none of the nodes within our <Agent> depend on each other they will run in parallel.
<!-- Targets that we will execute on a Windows machine. -->
<Agent Name="Windows Build" Type="UEWindowsRunner">
<!-- Compile the editor for Windows (necessary for cook later) -->
<Node Name="Compile $(EditorTarget) Win64" Produces="#EditorBinaries">
<Compile Target="$(EditorTarget)" Platform="Win64" Configuration="Development" Tag="#EditorBinaries" Arguments="-Project="$(UProjectPath)""/>
</Node>
<!-- Compile the game (targeting the Game target, not Client) -->
<ForEach Name="TargetPlatform" Values="$(GameTargetPlatformsBuiltOnWin)">
<ForEach Name="TargetConfiguration" Values="$(GameConfigurations)">
<Node Name="Compile $(GameTargets) $(TargetPlatform) $(TargetConfiguration)" Produces="#GameBinaries_$(GameTargets)_$(TargetPlatform)_$(TargetConfiguration)">
<Compile Target="$(GameTargets)" Platform="$(TargetPlatform)" Configuration="$(TargetConfiguration)" Tag="#GameBinaries_$(GameTargets)_$(TargetPlatform)_$(TargetConfiguration)" Arguments="-Project="$(UProjectPath)""/>
<Tag Files="#GameBinaries_$(GameTargets)_$(TargetPlatform)_$(TargetConfiguration)" Filter="*.target" With="#GameReceipts_$(GameTargets)_$(TargetPlatform)_$(TargetConfiguration)"/>
<SanitizeReceipt Files="#GameReceipts_$(GameTargets)_$(TargetPlatform)_$(TargetConfiguration)" />
</Node>
<Property Name="GameBinaries" Value="$(GameBinaries)#GameBinaries_$(GameTargets)_$(TargetPlatform)_$(TargetConfiguration);"/>
</ForEach>
</ForEach>
</Agent>
One thing I want to highlight here is that variable interpolation within the nodes properties is allowed.
We define a second agent for cooking our assets on windows:
<!-- Targets that we will execute on a Windows machine. -->
<Agent Name="Windows Cook" Type="UEWindowsRunner">
<!-- Cook for game platforms (targeting the Game target, not Client) -->
<ForEach Name="TargetPlatform" Values="$(GameTargetPlatformsCookedOnWin)">
<Node Name="Cook Game $(TargetPlatform) Win64" Requires="#EditorBinaries" Produces="#GameCookedContent_$(TargetPlatform)">
<Property Name="CookPlatform" Value="$(TargetPlatform)" />
<Property Name="CookPlatform" Value="Windows" If="'$(CookPlatform)' == 'Win64'" />
<Property Name="CookPlatform" Value="$(CookPlatform)" If="(('$(CookPlatform)' == 'Windows') or ('$(CookPlatform)' == 'Mac') or ('$(CookPlatform)' == 'Linux'))" />
<Cook Project="$(UProjectPath)" Platform="$(CookPlatform)" Arguments="-Compressed" Tag="#GameCookedContent_$(TargetPlatform)" />
</Node>
<Property Name="GameCookedContent" Value="$(GameCookedContent)#GameCookedContent_$(TargetPlatform);"/>
</ForEach>
</Agent>
Here we iterate through every platform that is allows to cook on windows, and we Requires="#EditorBinaries" meaning that this node is dependent on the editor for windows to be compiled first.
For each one of these we use the <Cook> task to cook the assets and we tag the resulting outputs to be used for packaging later.
We define our third and final agent for packaging on windows:
<!-- Targets that we will execute on a Windows machine. -->
<Agent Name="Windows Pak and Stage" Type="UEWindowsRunner">
<!-- Pak and stage the game (targeting the Game target, not Client) -->
<ForEach Name="TargetPlatform" Values="$(GameTargetPlatformsBuiltOnWin)">
<ForEach Name="TargetConfiguration" Values="$(GameConfigurations)">
<Node Name="Pak and Stage $(GameTarget) $(TargetPlatform) $(TargetConfiguration)" Requires="#GameBinaries_$(GameTarget)_$(TargetPlatform)_$(TargetConfiguration);#GameCookedContent_$(TargetPlatform)" Produces="#GameStaged_$(GameTarget)_$(TargetPlatform)_$(TargetConfiguration)" >
<Property Name="StagePlatform" Value="$(TargetPlatform)" />
<Property Name="StagePlatform" Value="Windows" If="'$(StagePlatform)' == 'Win64'" />
<Property Name="DisableCodeSign" Value="" />
<Property Name="DisableCodeSign" Value="-NoCodeSign" If="('$(TargetPlatform)' == 'Win64') or ('$(TargetPlatform)' == 'Mac') or ('$(TargetPlatform)' == 'Linux')" />
<Spawn Exe="c:\UnrealEngine\Engine\Build\BatchFiles\RunUAT.bat" Arguments="BuildCookRun -project=$(UProjectPath) -nop4 $(DisableCodeSign) -platform=$(TargetPlatform) -clientconfig=$(TargetConfiguration) -SkipCook -cook -pak -stage -stagingdirectory=$(StageDirectory) -compressed -unattended -stdlog" />
<Zip FromDir="$(StageDirectory)\$(StagePlatform)" ZipFile="$(ProjectRoot)\dist_win64.zip" />
<Tag BaseDir="$(StageDirectory)\$(StagePlatform)" Files="..." With="#GameStaged_$(GameTarget)_$(TargetPlatform)_$(TargetConfiguration)" />
</Node>
<Property Name="GameStaged" Value="$(GameStaged)#GameStaged_$(GameTarget)_$(TargetPlatform)_$(TargetConfiguration);" />
</ForEach>
</ForEach>
</Agent>
In a similar way we did for our compilation stage, we iterate trough every platrform we allow to be packaged on windows and for each configurations we are compiling, where we require the compiled game, the cooked assets and we package them for distribution.
At the time of writing, there’s no BuildGraph-native task to package the game so we call the classic BuildCookRun command from RunUAT.
After that we use the <Zip> task to compress our final result, and this is what we will be storing as an artifact.
I would like to point out here, the use of <Property> to manipulate values depending on conditionals set:
<Property Name="StagePlatform" Value="$(TargetPlatform)" />
<Property Name="StagePlatform" Value="Windows" If="'$(StagePlatform)' == 'Win64'" />
In this scenario we use it to transform from the Win64 value to Windows which is what UE supports.
Linux Agents (build, cook and pak)
The process of defining the steps for our Linux build, is mostly the same we will be changing the name of the Tags, the Agent Types and the paths to where we have Unreal Engine located on our Linux agents:
<!-- Targets that we will execute on a Linux machine. -->
<Agent Name="Linux Build" Type="UELinuxRunner">
<!-- Compile the editor for Linux (necessary for cook later) -->
<Node Name="Compile $(EditorTarget) Linux" Produces="#LinuxEditorBinaries">
<Compile Target="$(EditorTarget)" Platform="Linux" Configuration="Development" Tag="#LinuxEditorBinaries" Arguments="-Project="$(UProjectPath)""/>
</Node>
<!-- Compile the game (targeting the Game target, not Client) -->
<ForEach Name="TargetPlatform" Values="$(GameTargetPlatformsBuiltOnLinux)">
<ForEach Name="TargetConfiguration" Values="$(GameConfigurations)">
<Node Name="Compile $(GameTarget) $(TargetPlatform) $(TargetConfiguration)" Produces="#GameBinaries_$(GameTarget)_$(TargetPlatform)_$(TargetConfiguration)">
<Compile Target="$(GameTarget)" Platform="$(TargetPlatform)" Configuration="$(TargetConfiguration)" Tag="#GameBinaries_$(GameTarget)_$(TargetPlatform)_$(TargetConfiguration)" Arguments="-Project="$(UProjectPath)""/>
<Tag Files="#GameBinaries_$(GameTarget)_$(TargetPlatform)_$(TargetConfiguration)" Filter="*.target" With="#GameReceipts_$(GameTarget)_$(TargetPlatform)_$(TargetConfiguration)"/>
<SanitizeReceipt Files="#GameReceipts_$(GameTarget)_$(TargetPlatform)_$(TargetConfiguration)" />
</Node>
<Property Name="GameBinaries" Value="$(GameBinaries)#GameBinaries_$(GameTarget)_$(TargetPlatform)_$(TargetConfiguration);"/>
</ForEach>
</ForEach>
</Agent>
<Agent Name="Linux Cook" Type="UELinuxRunner">
<ForEach Name="TargetPlatform" Values="$(GameTargetPlatformsCookedOnLinux)">
<Node Name="Cook Game $(TargetPlatform) Linux" Requires="#LinuxEditorBinaries" Produces="#GameCookedContent_$(TargetPlatform)">
<Property Name="CookPlatform" Value="$(TargetPlatform)" />
<Property Name="CookPlatform" Value="Windows" If="'$(CookPlatform)' == 'Win64'" />
<Property Name="CookPlatform" Value="$(CookPlatform)" If="(('$(CookPlatform)' == 'Windows') or ('$(CookPlatform)' == 'Mac') or ('$(CookPlatform)' == 'Linux'))" />
<Cook Project="$(UProjectPath)" Platform="$(CookPlatform)" Arguments="-Compressed" Tag="#GameCookedContent_$(TargetPlatform)" />
</Node>
<Property Name="GameCookedContent" Value="$(GameCookedContent)#GameCookedContent_$(TargetPlatform);"/>
</ForEach>
</Agent>
<Agent Name="Linux Pak and Stage" Type="UELinuxRunner">
<!-- Pak and stage the dedicated server -->
<ForEach Name="TargetPlatform" Values="$(GameTargetPlatformsBuiltOnLinux)">
<ForEach Name="TargetConfiguration" Values="$(GameConfigurations)">
<Node Name="Pak and Stage $(GameTarget) $(TargetPlatform) $(TargetConfiguration)" Requires="#GameBinaries_$(GameTarget)_$(TargetPlatform)_$(TargetConfiguration);#GameCookedContent_$(TargetPlatform)" Produces="#GameStaged_$(GameTarget)_$(TargetPlatform)_$(TargetConfiguration)">
<Property Name="StagePlatform" Value="$(TargetPlatform)"/>
<Property Name="DisableCodeSign" Value="" />
<Property Name="DisableCodeSign" Value="-NoCodeSign" If="('$(TargetPlatform)' == 'Win64') or ('$(TargetPlatform)' == 'Mac') or ('$(TargetPlatform)' == 'Linux')" />
<Spawn Exe="/home/ubuntu/UnrealEngine/Engine/Build/BatchFiles/RunUAT.sh" Arguments="BuildCookRun -project=$(UProjectPath) -nop4 $(DisableCodeSign) -platform=$(TargetPlatform) -clientconfig=$(TargetConfiguration) -SkipCook -cook -pak -stage -stagingdirectory=$(StageDirectory) -compressed -unattended -stdlog" />
<Zip FromDir="$(StageDirectory)/$(StagePlatform)" ZipFile="$(ProjectRoot)/dist_linux.zip" />
<Tag BaseDir="$(StageDirectory)/$(StagePlatform)" Files="..." With="#GameStaged_$(GameTarget)_$(TargetPlatform)_$(TargetConfiguration)" />
</Node>
<Property Name="GameStaged" Value="$(GameStaged)#GameStaged_$(GameTarget)_$(TargetPlatform)_$(TargetConfiguration);" />
</ForEach>
</ForEach>
</Agent>
As you can see we mostly changed the Agent’s Type to UELinuxRunner, and all the paths to their Linux counterparts.
The aggregation agent
We finally create a dummy agent that we will be just using to aggregate all the tasks we defined earlier. This we will be using in our setup workflow to instruct BuildGraph that we want to execute all nodes.
<Agent Name="All" Type="UEWindowsRunner">
<!-- Node that we just use to easily execute all required nodes -->
<Node Name="End" Requires="$(GameStaged)">
</Node>
</Agent>
The full BuildGraph script
To recap we created a BuildGraph script that will generate the steps to:
- Compile the UE editor for cooking
- Cook the game assets
- Compile the game
- Package both assets and binaries into a distributable
And all of the above will be for both Windows and Linux platforms.
You can find the full BuildGraph script on the repository here
The translation layer
If you prefer to read the code instead of following this section of the tutorial, you can find all the code for the translation layer here.
Now that we have the BuildGraph script we need to figure out a way to translate this XML script to a CircleCI YAML workflow.
For that we are going to be creating a python translation layer, within this we are going to create a couple of classes:
- A base class
Runnerholding all of our pipeline steps with OS-agnostic code, as we will be running BuildGraph on both Linux and Windows we need to take into account that both OSes use different shells and certain steps are going to be different, e.g: setting and reading environment variables. - A
UEWindowsRunnerclass that inherits fromRunnerand will contain all Windows-specific code - A
UELinuxRunnerclass that inherits fromRunnerand will contain all Linux-specific code
As you can see our class names are the same as the Agent Types we defined in our BuildGraph script, this is no coincidence, we will be using Reflection to instantiate the classes.
Create a buildgraph-to-circleci directory inside Tools, and inside of it create:
- A
buildgraph-to-circleci.pyscript. - A
common.pyscript - A runners directory and within that:
__init__.py- Expose the classes within the runners directory.runner.py- this is our base class and contains all the CircleCI workflow logicue_linux_runner.py- Linux class with OS-specific codeue_windows_runner.py- Windows class with OS-specific code
First we create some common functions in common.py
# common.py
# This will add support for multiline string in PyYAML
def yaml_multiline_string_pipe(dumper, data):
text_list = [line.lstrip().rstrip() for line in data.splitlines()]
fixed_data = "\n".join(text_list)
if len(text_list) > 1:
return dumper.represent_scalar('tag:yaml.org,2002:str', fixed_data, style="|")
return dumper.represent_scalar('tag:yaml.org,2002:str', fixed_data)
# Will use this to sanitize job names, removing spaces with hyphens.
def sanitize_job_name(name):
return name.replace(' ', '-').lower()
These are some functions that we will be using in several other Python files. One is to add better support for multiline string in YAML for the final CircleCI workflow, the other one is to do some sanitization for the job names by replacing spaces with hyphens.
The buildgraph-to-circleci.py is the main script we will be executing on our setup workflow, this will receive the BuildGraph exported JSON, it’ll iterate through it and using reflection will instantiate the correct runner class that will end up generating the steps for the build-game workflow:
#!/usr/bin/env python3
import json
import yaml
import argparse
import os
import sys
import importlib
from common import yaml_multiline_string_pipe, sanitize_job_name
# We create some arguments that we need to execute the script.
parser = argparse.ArgumentParser()
parser.add_argument("--json-graph", required=True, help="Path to Graph in JSON format")
parser.add_argument("--git-branch", default=os.getenv("CIRCLE_BRANCH", ""), help="Branch that triggered the pipeline")
parser.add_argument("--git-commit", default=os.getenv("CIRCLE_SHA1", ""), help="Commit that triggered the pipeline")
args = parser.parse_args()
if not args.git_branch or not args.git_commit:
print("--git-branch and --git-commit are required. Or CIRCLE_BRANCH and CIRCLE_SHA1 variables should be defined")
parser.print_help(sys.stderr)
parser.exit(1)
graph = None
# Create an empty boilerplate object that we will fill with jobs for CircleCI
# We create a workflow named build-game
circleci_manifest = {
'version': 2.1,
'parameters': {
},
'jobs': {
},
'workflows': {
'build-game': {
'jobs': [
]
}
}
}
# Load the Exported JSON BuildGraph
with open(args.json_graph, "r") as stream:
try:
graph = json.load(stream)
except Exception as exc:
print(exc)
## Loop over the generated jobs
for group in graph["Groups"]:
for node in group["Nodes"]:
# Sanitize the node name BuildGraph gives us. Replacing spaces with hyphens and lowercase.
sanitized_name = sanitize_job_name(node['Name'])
# The End node is an additional node that buildgraph creates that depends on all nodes being executing, there's no actual logic here to execute
# so we check if we should skip.
if "end" in sanitized_name:
continue
# Using reflection load the runner class defined in the 'Agent Type' field on BuildGraph
Class = getattr(importlib.import_module("runners"), group['Agent Types'][0])
# The git branch is the only required parameter for our constructor.
runner = Class(args.git_branch)
# Generate the job for this Node
steps = runner.generate_steps(node['Name'])
# Add the job to our manifest
circleci_manifest['jobs'][sanitized_name] = {
'shell': runner.shell,
'machine': True,
'working_directory': runner.working_directory,
'resource_class': runner.resource_class,
'environment': runner.environment,
'steps': steps
}
job = {
sanitized_name: {
}
}
# Set the dependencies for each job
if node["DependsOn"] != "":
if not 'requires' in job[sanitized_name]:
job[sanitized_name]['requires'] = []
# The depdencies are in a semicolon-separated list.
depends_on = [sanitize_job_name(d) for d in node["DependsOn"].split(";")]
job[sanitized_name]['requires'].extend(depends_on)
# Add the job to the build-game workflow
circleci_manifest['workflows']['build-game']['jobs'].append(job)
## Print the final YAML
yaml.add_representer(str, yaml_multiline_string_pipe)
yaml.representer.SafeRepresenter.add_representer(str, yaml_multiline_string_pipe)
print(yaml.dump(circleci_manifest))
Our main script receives the Path to the BuildGraph exported Graph in JSON format and it iterates through it. Each node in the graph has the Agent Type where the job has to run, we take that and we instantiate the Python class of the same name, then it will call the generate_steps method to get the steps for the job that we will execute in the workflow.
Finally it will set which jobs depend on each other in the workflow.
Now we create in runners/runner.py our base Runner class:
from common import sanitize_job_name
class Runner:
def __init__(self):
# This will determine the resource class the runner will use
self.resource_class = ''
# The location of the RunUAT script
self.run_uat_subpath = ''
# The prefix to read an environment variable in the OS
self.env_prefix = ''
# The prefix to assign a value to an environment variable
self.env_assignment_prefix = ''
# The shell the runner will be using
self.shell = ''
# Any environment variables we want to include in our job execution
self.environment = {}
# The path to unreal engine
self.ue_path = ''
# The working directory for the jobs
self.working_directory = ''
# The shared storage BuildGraph will use
self.shared_storage_volume = ''
# The name of the branch we are running
self.branch_name = ''
# These methods have to be overloaded/overriden by the classes that inherit Runner
# they have to return the OS-specific way to execute these actions.
def mount_shared_storage(self):
raise NotImplementedError("Runners have to implement this")
def create_dir(self, directory):
raise NotImplementedError("Runners have to implement this")
def pre_cleanup(self):
raise NotImplementedError("Runners have to implement this")
def self_patch_buildgraph(self):
return f"git -C {self.ue_path} apply {self.env_prefix}CIRCLE_WORKING_DIRECTORY/Tools/BuildGraph.patch"
def patch_buildgraph(self):
self.self_patch_buildgraph()
def generate_steps(self, job_name):
return self.generate_buildgraph_steps(job_name)
# These return all the steps to run for the job
def generate_buildgraph_steps(self, job_name):
sanitized_job_name = sanitize_job_name(job_name)
filesafe_branch_name = self.branch_name.replace("/", "_")
steps = [
# Checkout our code
"checkout",
# Mount our shared storage
{
'run': {
'name': 'Mount Shared Storage (FSx)',
'command': self.mount_shared_storage()
}
},
# Create a directory within our shared storage specific for our branch/commit combination.
{
'run': {
'name': "Create shared directory for workflow",
'command': f"""{self.create_dir(f"{self.shared_storage_volume}{filesafe_branch_name}/{self.env_prefix}CIRCLE_SHA1")}
"""
}
},
# We do some cleanup previous to running BuildGraph
{
'run': {
'name': "Cleanup old build",
'command': self.pre_cleanup()
}
},
# We patch BuildGraph
{
'run': {
'name': "Apply BuildGraph patch",
'command': self.patch_buildgraph()
}
},
# Here we run our current BuildGraph node.
# Environment variables used:
# BUILD_GRAPH_ALLOW_MUTATION - To allow for file mutations
# uebp_UATMutexNoWait - Allows UE5 to execute multiple instances of RunUAT
# uebp_LOCAL_ROOT - The location of our Unreal Engine Build
# BUILD_GRAPH_PROJECT_ROOT - The working location of our project
#
# We always run the same BuildGraph command calling the specific Node we have to run for the step. Then BuildGraph takes care of the rest.
{
'run': {
'name': job_name,
'command': f"""
{self.env_assignment_prefix}BUILD_GRAPH_ALLOW_MUTATION=\"true\"
{self.env_assignment_prefix}uebp_UATMutexNoWait=\"1\"
{self.env_assignment_prefix}uebp_LOCAL_ROOT=\"{self.ue_path}\"
{self.env_assignment_prefix}BUILD_GRAPH_PROJECT_ROOT=\"{self.env_prefix}CIRCLE_WORKING_DIRECTORY\"
{self.ue_path}{self.run_uat_subpath} BuildGraph -Script=\"{self.env_prefix}CIRCLE_WORKING_DIRECTORY/Tools/BuildGraph.xml\" -SingleNode=\"{job_name}\" -set:ProjectRoot=\"{self.env_prefix}CIRCLE_WORKING_DIRECTORY\" -set:UProjectPath=\"{self.env_prefix}CIRCLE_WORKING_DIRECTORY/FirstPersonGame.uproject\" -set:StageDirectory=\"{self.env_prefix}CIRCLE_WORKING_DIRECTORY/dist\" -SharedStorageDir=\"{self.shared_storage_volume}{filesafe_branch_name}/{self.env_prefix}CIRCLE_SHA1\" -NoP4 -WriteToSharedStorage -BuildMachine
"""
}
}
]
pak_steps = []
# We check if we have the word 'pak' on our job name (this will come from our buildgraph script)
# To know if we have to upload an artifact after running BuildGraph
if "pak" in sanitized_job_name:
suffix = ""
if "win64" in sanitized_job_name:
suffix = "_win64"
elif "linux" in sanitized_job_name:
suffix = "_linux"
# We upload the produced artifact
pak_steps.extend([
{
'store_artifacts': {
'path': f'dist{suffix}.zip'
}
}
])
steps.extend(pak_steps)
return steps
This base class defines all attributes that need to be passed down such as location of the Unreal Engine directory and how to assign environment variables. Then it also defines some methods that have to be overridden by the classes that inherit; for example: create a directory, the commands are slightly different in Linux and Windows. Then the generate_buildgraph_steps method will output the corresponding CircleCI workflow that will be the same no matter the OS.
Now that we have our OS-agnostic code, we create both the Linux and Windows classes in runners/ue_linux_runner.py and runners/ue_windows_runner.py respectively.
# runners/ue_linux_runner.py
from .runner import Runner
class UELinuxRunner(Runner):
def __init__(self, branch_name):
Runner.__init__(self)
self.branch_name = branch_name
self.env_prefix = '$'
self.env_assignment_prefix = 'export '
self.environment = {
'UE_SharedDataCachePath': '/data_fsx/SharedDDCUE5Test'
}
self.resource_class = 'vela-games/linux-runner-ue5'
self.run_uat_subpath = '/Engine/Build/BatchFiles/RunUAT.sh'
self.shell = '/usr/bin/env bash'
self.shared_storage_volume = '/data_fsx/'
self.ue_path = '/home/ubuntu/UnrealEngine'
self.working_directory = f'/home/ubuntu/workspace/{branch_name.replace("/","-").replace("_", "-").lower()}'
def patch_buildgraph(self):
return f'{self.self_patch_buildgraph()} || true'
def mount_shared_storage(self):
return 'echo "Linux already mounted"'
def create_dir(self, directory):
return f"mkdir -p {directory}"
def pre_cleanup(self):
return """rm -rf *.zip
rm -rf /home/ubuntu/UnrealEngine/Engine/Saved/BuildGraph/
rm -rf $CIRCLE_WORKING_DIRECTORY/Engine/Saved/*
rm -rf $CIRCLE_WORKING_DIRECTORY/dist
"""
# runners/ue_windows_runner.py
from .runner import Runner
class UEWindowsRunner(Runner):
def __init__(self, branch_name):
Runner.__init__(self)
self.branch_name = branch_name
self.env_prefix = '$Env:'
self.env_assignment_prefix = '$Env:'
self.environment = {
'UE-SharedDataCachePath': 'Z:\\SharedDDCUE5Test'
}
self.resource_class = 'vela-games/windows-runner-ue5'
self.run_uat_subpath = '\\Engine\\Build\\BatchFiles\\RunUAT.bat'
self.shell = 'powershell.exe'
self.shared_storage_volume = 'Z:\\'
self.ue_path = 'C:\\UnrealEngine'
self.working_directory = f'C:\\workspace\\{branch_name.replace("/","-").replace("_", "-").lower()}'
def patch_buildgraph(self):
return f"""{self.self_patch_buildgraph()}
[Environment]::Exit(0)
"""
# This script we are creating in the user-data on our TF module. See above in the tutorial
def mount_shared_storage(self):
return "C:\\mount_fsx.ps1"
def create_dir(self, directory):
return f"New-Item -ItemType 'directory' -Path \"{directory}\" -Force -ErrorAction SilentlyContinue"
def pre_cleanup(self):
return """Remove-Item -Force *.zip -ErrorAction SilentlyContinue
Remove-Item -Force -Recurse \"C:\\UnrealEngine\\Engine\\Saved\\BuildGraph\\\" -ErrorAction SilentlyContinue
Remove-Item -Force -Recurse \"$Env:CIRCLE_WORKING_DIRECTORY\\Engine\\Saved\\*\" -ErrorAction SilentlyContinue
Remove-Item -Force -Recurse \"$Env:CIRCLE_WORKING_DIRECTORY\\dist\\\" -ErrorAction SilentlyContinue
[Environment]::Exit(0)
"""
As you can see for both of these we only set the class attributes and methods with the OS-specific actions. Then the base Runner class will take care of the heavy lifting.
Within runners/__init__.py add:
# runners/__init__.py
from .ue_linux_runner import UELinuxRunner
from .ue_windows_runner import UEWindowsRunner
This is needed so we can import the classes on our main script.
The CircleCI setup workflow
Now that we have our translation layer we can create our circleci config file to finally execute our pipeline!
Within your project create the .circleci/config.yml file and add the following:
version: 2.1
setup: true
orbs:
continuation: circleci/continuation@0.1.2
jobs:
setup:
machine: true
resource_class: vela-games/your-linux-class
steps:
- checkout
# Here we run BuildGraph only to "Compile" our BuildGraph script and export the JSON Graph
# We then pass it down to our translation layer and redirect the output to a yml file that the continuation orb will send to CircleCI's API
- run: |
/home/ubuntu/UnrealEngine/Engine/Build/BatchFiles/RunUAT.sh BuildGraph -Target=All -Script=$PWD/Tools/BuildGraph.xml -Export=$PWD/ExportedGraph.json
./Tools/buildgraph-to-circleci/buildgraph-to-circleci.py --json-graph $PWD/ExportedGraph.json > /tmp/generated_config.yml
- continuation/continue:
configuration_path: /tmp/generated_config.yml
workflows:
setup:
jobs:
- setup
This runs the setup job on a Linux self-hosted runner, in it we:
- Run BuildGraph targetting out aggregate node and with the
-Exportparameter we instruct it to only output the resulting graph as a JSON file - We then pass the exported Graph into the
buildgraph-to-circleci.pytranslation script and we redirect the output to a temporary file - Using the continuation orb we pass the generated YAML workflow.
And if all went well this is the resulting workflow you will see:
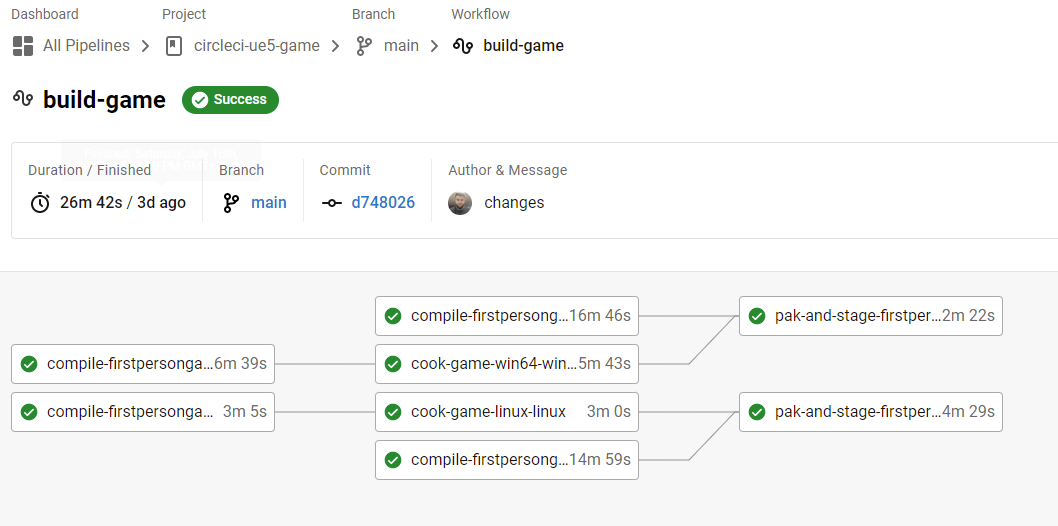
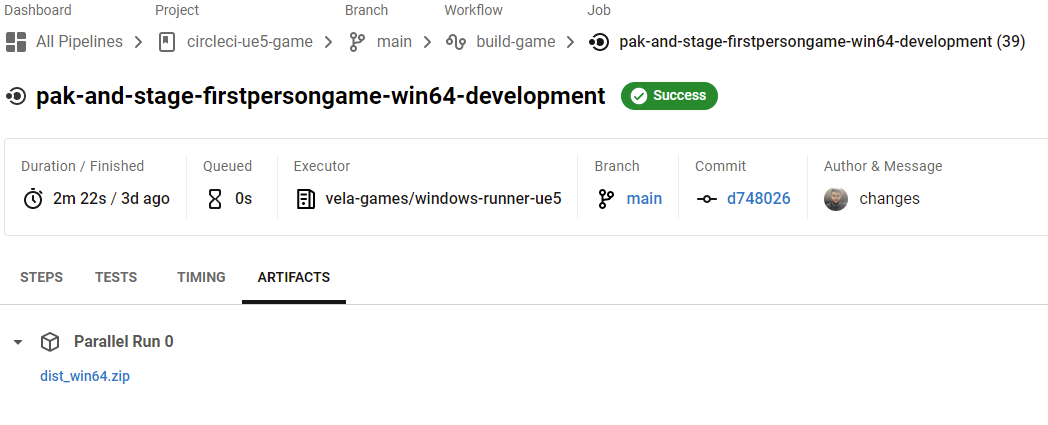
And will be able to download the built game from the Artifacts tab on the pak job both Win64 and Linux:
Recap
In this tutorial we demonstrated how to integrate Unreal Engine’s BuildGraph Automation System with CircleCI, by creating an layer that translates from BuildGraph’s JSON Graphs to CircleCI’s YAML definition and how to use CircleCI’s self-runner offering as the job executors.
As mentioned in our introduction, this enables for faster parallelalized builds when compared to the regular BuildCookRun script.
To be able to achieve this we:
- Deployed self-hosted runners and FSx (shared storage solution) on AWS using terraform
- Created a BuildGraph script to compile, cook and package a game on both windows and linux platforms
- Created a python translation layer that translates from a BuildGraph JSON Graph to a CircleCI Workflow definition
- Used the Dynamic Configuration to dynamically create our build workflow
We hope you can use this same technique, that allowed us to reduce our build times up to 85%, as a base for the build automation of your next Unreal Engine project, or to accelerate the development of an existing one.
Our adventures don’t end here. Stay tuned for more thrilling tales, magical mishaps, and epic engineering escapades. Until then, keep your code clean, your builds smooth, and remember: in the world of DevOps, recycling is not just for paper and plastics, it’s for building an extraordinary tech universe. Happy coding, and may the DevOps force be with you! 🌟🚀🎉
If you have any comments feel free to leave them below!